

Genel
Replica Set
Replica Set Nedir?
Replica Set, aynı veri setinin birden fazla MongoDB sunucusunda tutulmasını sağlayan yüksek erişilebilirlik ve veri sürekliliği mimarisidir. Bir Replica Set yapısında genellikle bir adet Primary node ve bir veya daha fazla Secondary node bulunur.
Primary node, yazma işlemlerinin gerçekleştirildiği ana sunucudur. Secondary node'lar ise Primary üzerinde gerçekleşen değişiklikleri oplog üzerinden takip eder ve bu değişiklikleri kendi veri setlerine uygular. Bu sayede veri, Replica Set içerisindeki tüm node'larda güncel olarak tutulur.
Primary node üzerinde bir problem oluşması durumunda, uygun bir Secondary node otomatik olarak yeni Primary olarak seçilebilir. Bu seçim işlemine election adı verilir. Böylece sistem, uygun mimari sağlandığında manuel müdahale gerektirmeden yazma işlemlerine devam edebilir.
Replica Set kurulumlarında en az üç node kullanılması önerilir. İki node ile de Replica Set oluşturulabilir; ancak bu yapı yüksek erişilebilirlik açısından yeterli değildir. Çünkü Primary node erişilemez hale geldiğinde geriye kalan tek node majority sağlayamaz. Majority sağlanamadığı için mevcut Secondary node otomatik olarak Primary rolünü üstlenemez ve yazma işlemleri durur.
Replica Set'in temel amacı veri yedekliliği, yüksek erişilebilirlik ve otomatik failover sağlamaktır. Ancak Replica Set bir yedekleme çözümü değildir. Primary üzerinde yapılan silme, güncelleme veya hatalı veri değişiklikleri Secondary node'lara da replike edilir. Ayrıca belirli bir zamana geri dönüş (point-in-time recovery) özelliği sunmaz. Bu nedenle Replica Set mimarisi her zaman düzenli bir backup stratejisi ile birlikte planlanmalıdır.
Replica Set Neden Kullanılır?
Tek bir MongoDB sunucusu kullanıldığında, donanım arızaları, işletim sistemi problemleri, disk sorunları veya MongoDB servis kesintileri uygulamanın veritabanına erişememesine neden olabilir.
Replica Set kullanıldığında veri birden fazla node üzerinde tutulduğu için tek bir sunucunun kaybedilmesi sistemin tamamen durmasına neden olmaz. Uygun şartlar sağlandığında yeni bir Primary seçilir ve uygulama veritabanı işlemlerine devam edebilir.
Replica Set'ler genel olarak aşağıdaki ihtiyaçlar için kullanılır:
1. Yüksek Erişilebilirlik Sağlamak
Primary node erişilemez hale geldiğinde Replica Set üyeleri kendi aralarında seçim yapar ve uygun bir Secondary node yeni Primary olarak seçilir. Bu işleme election adı verilir ve MongoDB tarafından otomatik olarak yönetilir.
2. Veri Kaybı Riskini Azaltmak
Veri yalnızca tek bir sunucuda tutulmaz. Secondary node'lara da replike edilir. Böylece Primary node kaybedilse bile verinin güncel kopyaları diğer üyelerde bulunmaya devam eder.
3. Bakım İşlemlerini Daha Güvenli Gerçekleştirmek
Sunucu güncellemeleri, yeniden başlatma işlemleri, işletim sistemi bakımları ve MongoDB sürüm yükseltmeleri node'lar üzerinde sırayla gerçekleştirilebilir. Böylece tüm sistemi kapatmadan bakım işlemleri tamamlanabilir.
4. Okuma Yükünü Dağıtmak
Varsayılan olarak hem okuma hem de yazma işlemleri Primary node üzerinden gerçekleştirilir. Ancak uygulama tarafında read preference ayarı kullanılarak belirli okuma işlemleri Secondary node'lara yönlendirilebilir.
Read preference, istemcilerin okuma isteklerini Replica Set üyeleri arasında nasıl dağıtacağını belirleyen mekanizmadır.
5. Disaster Recovery Senaryoları Oluşturmak
Farklı lokasyonlarda Secondary node'lar konumlandırılarak veri merkezi kaynaklı kesintilere karşı daha dayanıklı bir mimari oluşturulabilir.
Örneğin Primary node Ankara'da, bir Secondary node ise İstanbul'da bulunabilir. Bu yaklaşım, disaster recovery planlamalarında önemli avantajlar sağlar.
Replica Set Nasıl Çalışır?
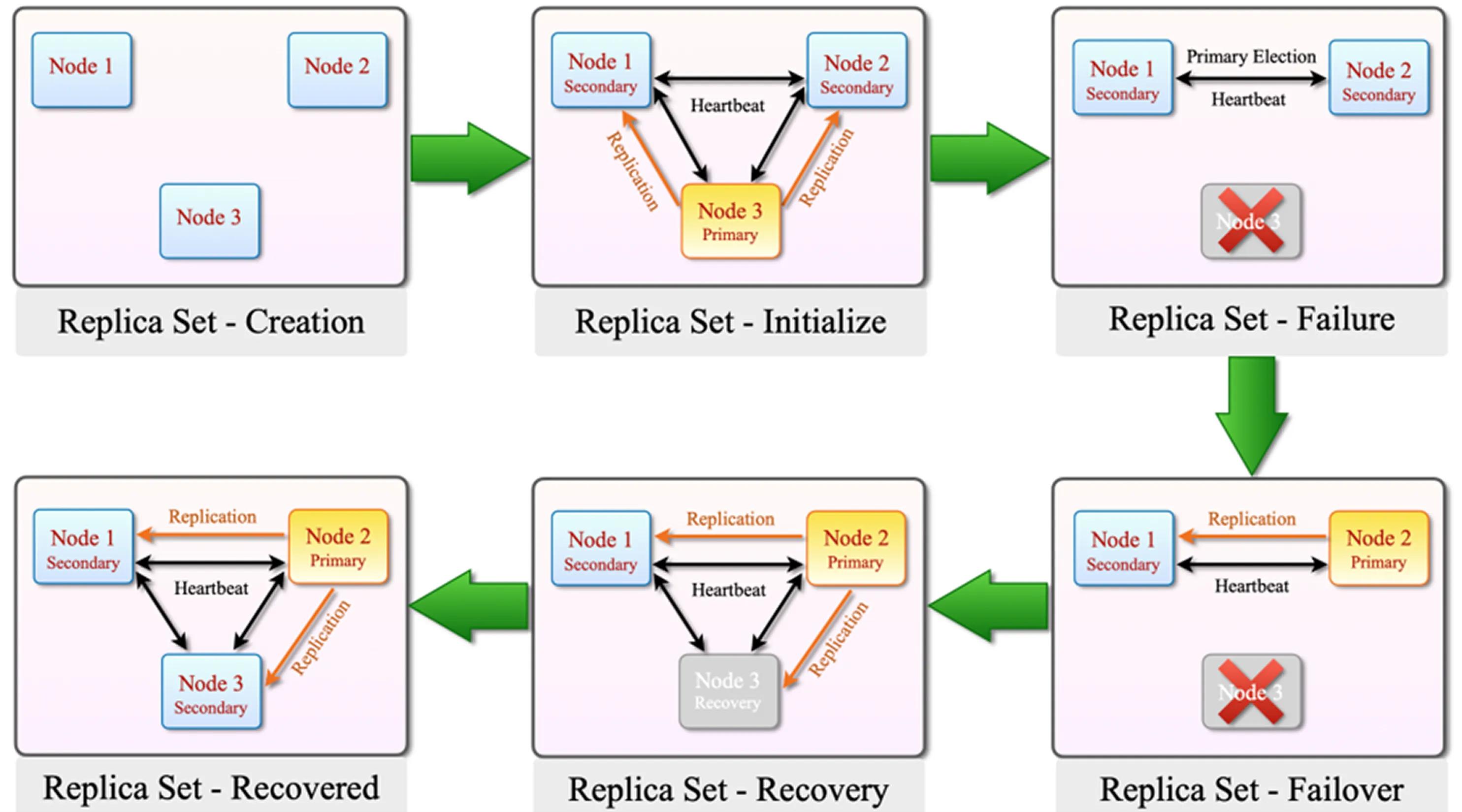
Replica Set Nasıl Çalışır?
Bir MongoDB Replica Set'in çalışma mantığı; election, failover ve senkronizasyon süreçleri üzerine kuruludur. Aşağıdaki örnek senaryo, Replica Set'in bir arıza durumunda nasıl davranacağını göstermektedir.
1. Replica Set – Creation
Başlangıçta Replica Set'e dahil edilmek üzere üç MongoDB node hazırlanır.
İki node ile de Replica Set başlatılabilir; ancak majority sağlanamayacağı için bu yapı yüksek erişilebilirlik açısından uygun değildir.
2. Replica Set – Initialize
Replica Set başlatıldığında node'lar birbirleriyle haberleşmeye başlar. Bu iletişim heartbeat mekanizması ile sağlanır.
Heartbeat sayesinde node'lar birbirlerinin erişilebilir olup olmadığını sürekli olarak kontrol eder.
Ardından election adı verilen seçim süreci gerçekleşir ve node'lardan biri Primary olarak seçilir. Diğer node'lar ise Secondary olarak çalışmaya devam eder.
Bu aşamadan sonra:
Yazma işlemleri Primary node üzerinden gerçekleştirilir.
Secondary node'lar Primary üzerinde oluşan oplog kayıtlarını takip eder.
Oplog kayıtları uygulanarak veriler senkron tutulur.
3. Replica Set – Failure
Primary olan Node 3 arızalanır veya erişilemez hale gelir.
Replica Set üyeleri heartbeat mekanizması sayesinde Node 3'ün artık cevap vermediğini algılar.
Primary erişilemez hale geldiği için Replica Set içerisinde yeni bir Primary seçimi yapılması gerekir.
4. Replica Set – Failover
Node 3 erişilemez hale geldikten sonra kalan uygun üyeler arasında election gerçekleştirilir.
Bu sürece failover adı verilir.
Eski Primary artık erişilebilir olmadığı için sistem uygun bir Secondary node'u otomatik olarak yeni Primary olarak seçer. Böylece veritabanı tamamen durmak yerine yeni Primary üzerinden çalışmaya devam eder.
5. Replica Set – Recovery
Arızalanan Node 3 tekrar ayağa kalktığında doğrudan Primary olmaz.
Öncelikle Replica Set'e yeniden katılır ve eksik verilerini tamamlamaya başlar.
Eksik kalan oplog kayıtlarını mevcut Primary'den veya uygun bir sync source üzerinden alır ve kendi üzerine uygular.
Bu süreç recovery veya synchronization olarak adlandırılır.
6. Replica Set – Recovered
Node 3 eksik replikasyon kayıtlarını tamamladıktan sonra tekrar sağlıklı bir Secondary olarak çalışmaya devam eder.
Eski Primary olan Node 3 geri geldiğinde otomatik olarak yeniden Primary rolünü üstlenmez. Mevcut Primary hizmet vermeye devam eder.
Özet
MongoDB Replica Set yapısında node'lar heartbeat mekanizması ile birbirlerinin durumunu kontrol eder.
Primary node erişilemez hale geldiğinde kalan uygun üyeler arasında election yapılır ve yeni bir Primary seçilir.
Arızalanan node tekrar ayağa kalktığında eksik verilerini senkronize eder ve genellikle Secondary olarak sisteme dahil olur.
Bu yapı sayesinde MongoDB tarafında yüksek erişilebilirlik ve otomatik failover sağlanır.
Veriler Replica Sunuculara Nasıl Yazılır?
MongoDB'de oplog, Replica Set yapısında gerçekleşen veri değişikliklerinin kayıt altına alındığı özel bir log yapısıdır.
Primary node üzerinde yapılan insert, update ve delete işlemleri oplog'a yazılır.
Secondary node'lar ise bu oplog kayıtlarını takip ederek aynı işlemleri kendi verileri üzerinde uygular.
MongoDB Replica Set replikasyonunun temelinde oplog mekanizması bulunur.
Oplog Nerede Tutulur?
Oplog kayıtları, her Replica Set üyesinde local veritabanı altında bulunan oplog.rs koleksiyonunda tutulur.
Oplog kayıtlarını görüntülemek için:
Son oplog kayıtlarını görüntülemek için:
Oplog Nasıl Çalışır?
Uygulama yazma işlemini Primary node'a gönderir.
Primary node değişikliği kendi verisi üzerinde uygular ve aynı zamanda ilgili işlemi oplog'a kaydeder.
Secondary node'lar oplog kayıtlarını sürekli takip eder ve bu kayıtları kendi üzerlerinde uygulayarak Primary ile senkron kalır.
Replikasyon süreci aşağıdaki şekilde gerçekleşir:
Uygulama Primary node'a insert, update veya delete işlemi gönderir.
Primary node işlemi kendi verisine uygular.
İşlem oplog'a yazılır.
Secondary node'lar oplog kayıtlarını okur.
Secondary node'lar aynı işlemleri kendi veri setlerine uygular.
Böylece Replica Set içerisindeki tüm üyeler senkron kalır.
Oplog Kayıtlarında Hangi Alanlar Bulunur?
Oplog kayıtlarında genellikle aşağıdaki alanlar yer alır:
Alan | Açıklama |
|---|---|
ts | İşlemin timestamp bilgisi |
op | Operasyon tipi |
ns | İşlemin yapıldığı namespace ( |
o | Yapılan işlemin içeriği |
o2 | Özellikle update işlemlerinde güncellenen dokümanı tanımlar |
op alanında bulunan değerler:
Değer | Anlamı |
|---|---|
i | Insert |
u | Update |
d | Delete |
c | Command |
n | No-op |
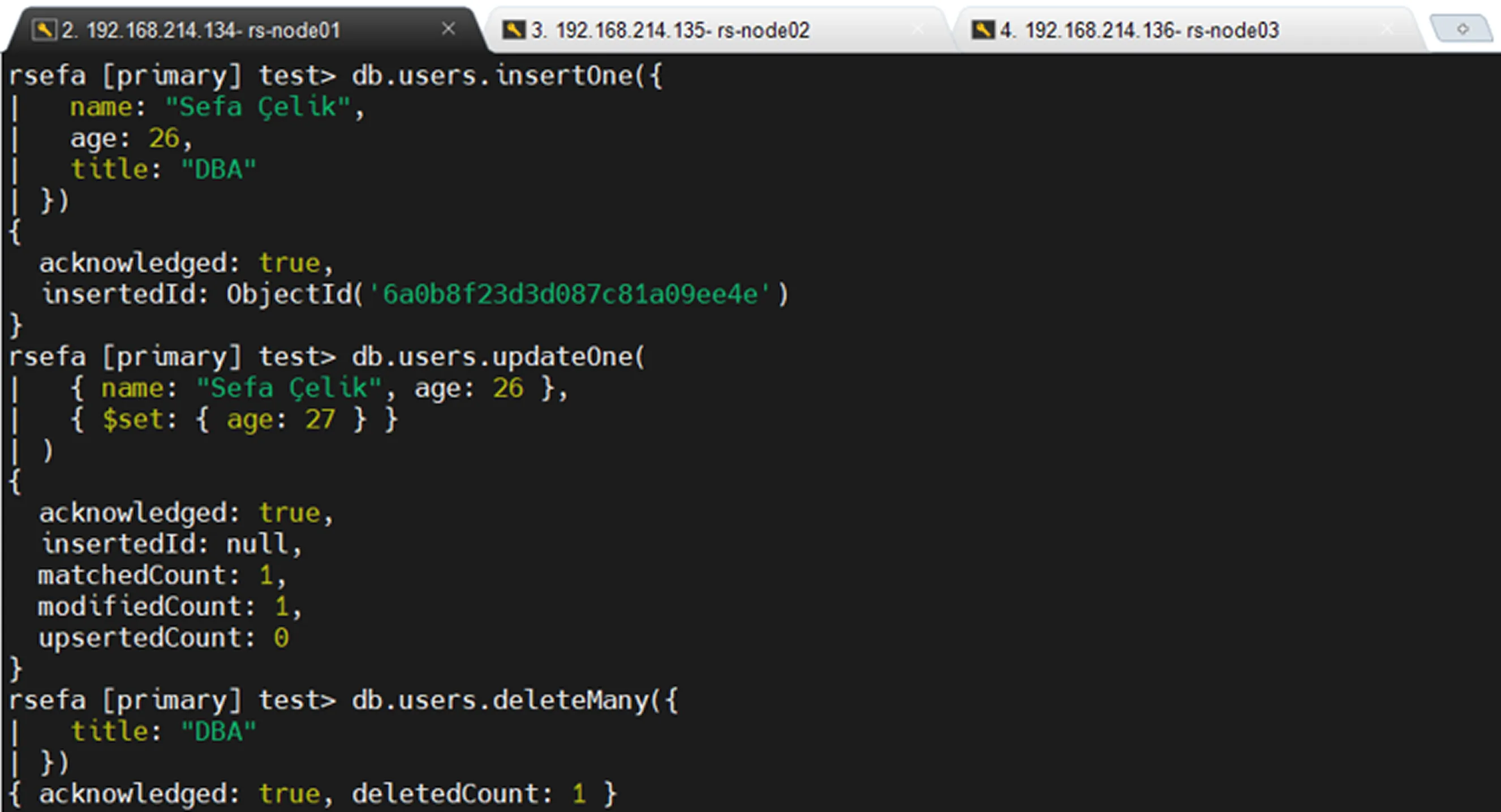
Oplog Kayıtlarını Test Etmek
Oplog kayıtlarını gözlemlemek için aşağıdaki örnek işlemler gerçekleştirilebilir.
Insert
Update
Delete
use local
Sadece Insert Kayıtlarını Görüntüleme
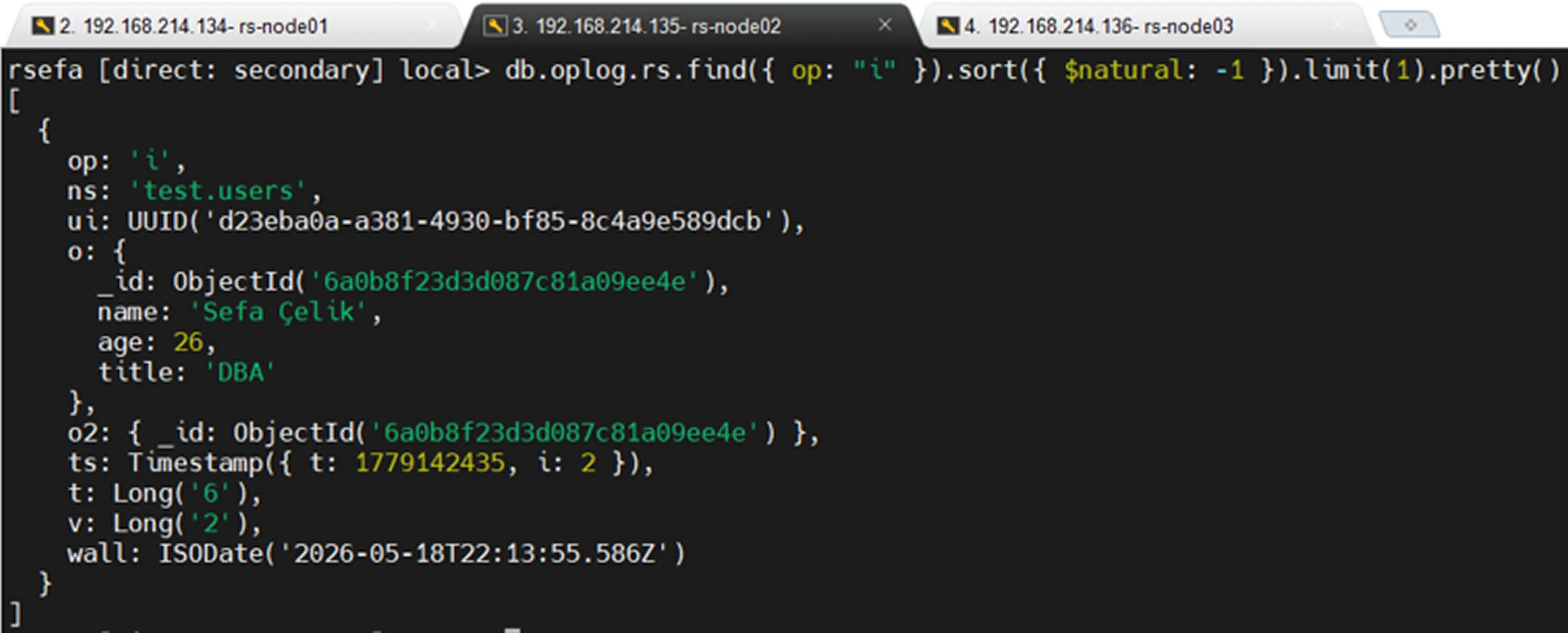
Sadece Update Kayıtlarını Görüntüleme
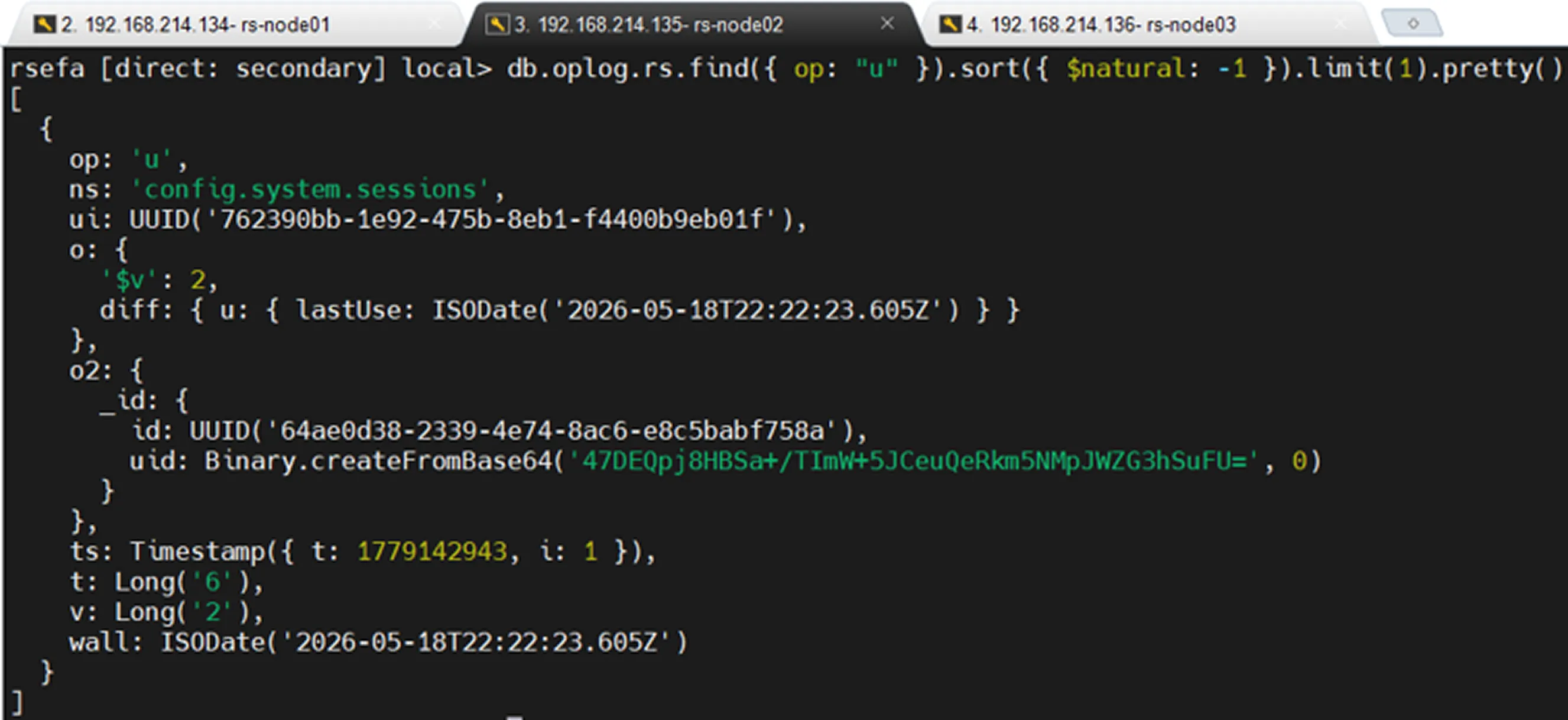
Sadece Delete Kayıtlarını Görüntüleme
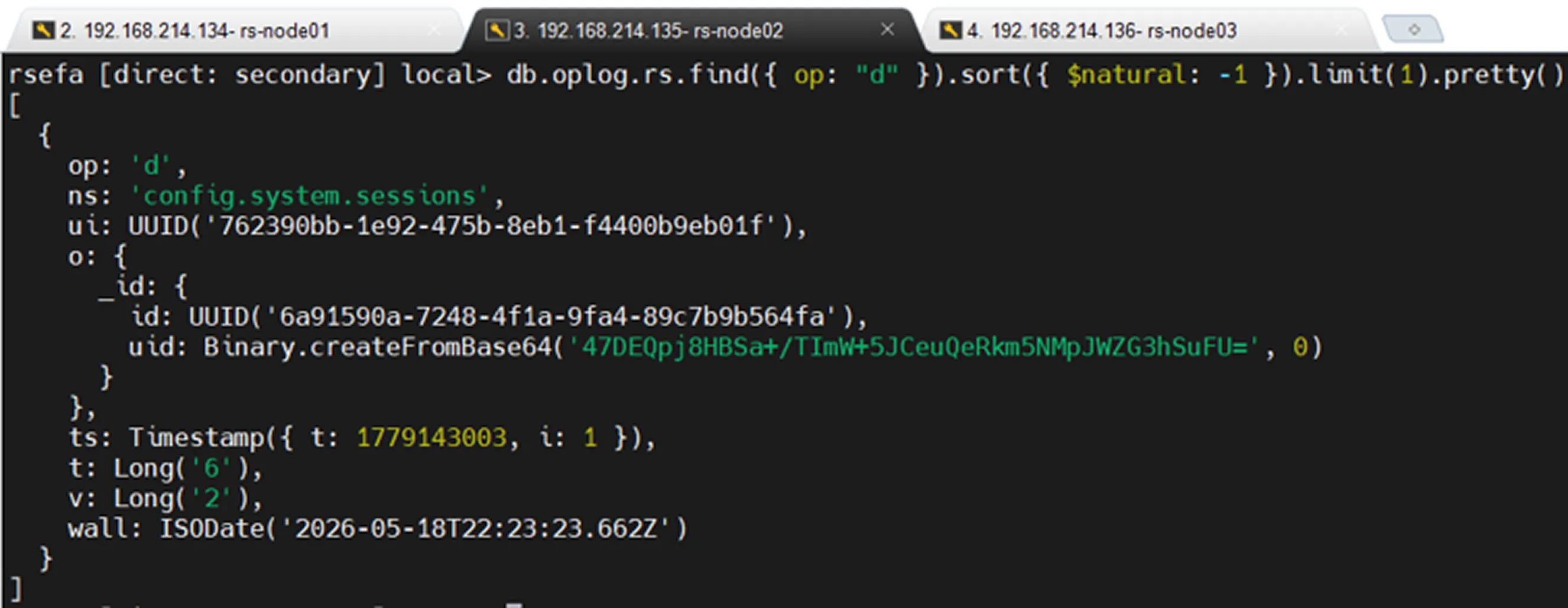
Oplog sınırsız büyüyen bir yapı değildir. Capped collection mantığıyla çalışır. Yani belirli bir boyutu vardır. Bu alan doldukça en eski oplog kayıtları silinir ve yeni kayıtlar yazılır.
Bu nedenle oplog boyutu çok önemlidir. Eğer Secondary node uzun süre kapalı kalırsa ve bu süre içinde Primary üzerindeki eski oplog kayıtları silinirse, Secondary node kaldığı yerden devam edemez. Bu durumda Secondary node’un tekrar initial sync yapması gerekir.
Oplog boyutunu ve durumunu görmek için:
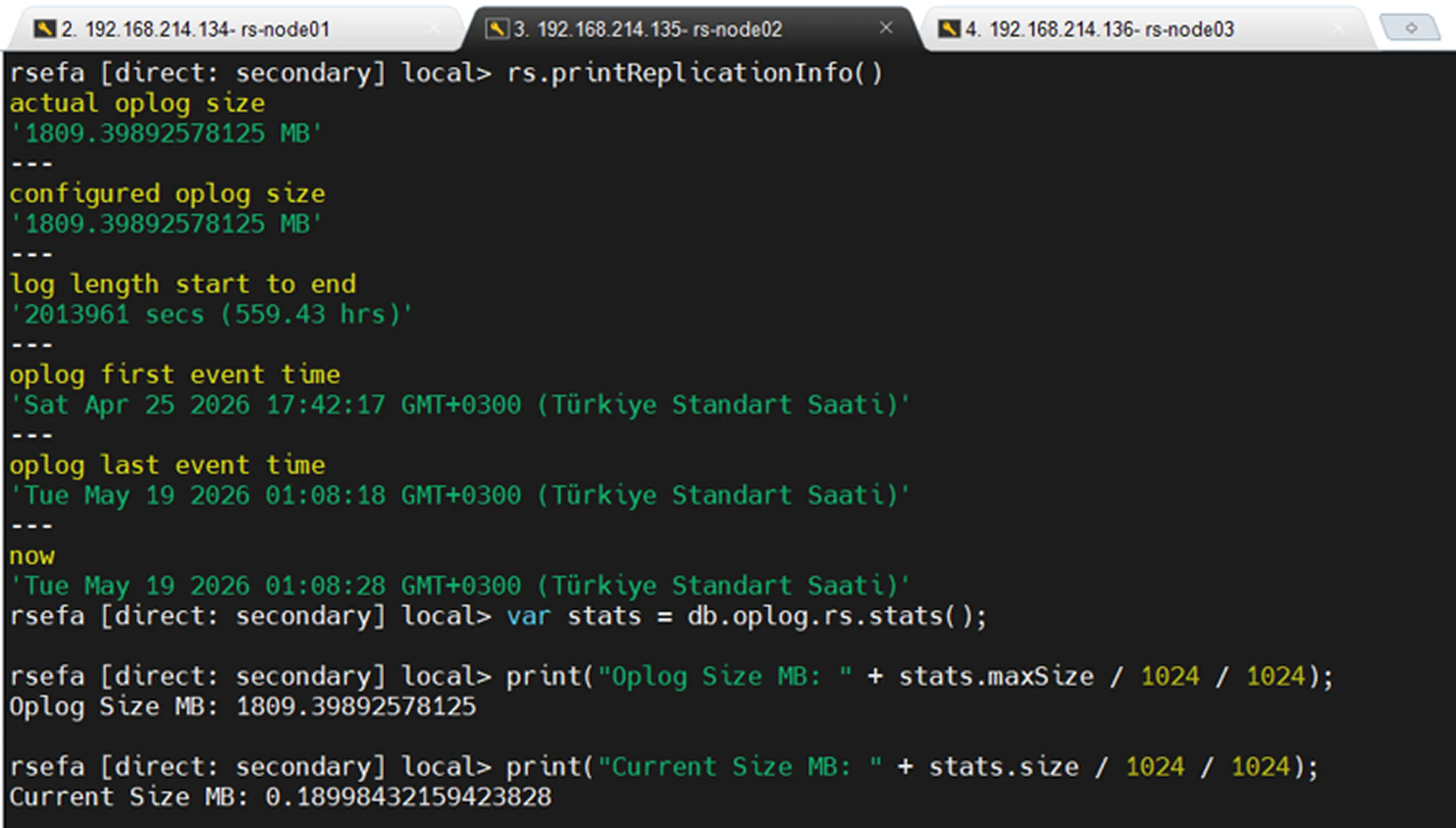
Bu çıktıya göre oplog yaklaşık 23 günlük geçmişi tutmaktadır. Bir secondary node 23 günden fazla kapalı kalırsa, geri geldiğinde primary üzerindeki gerekli eski oplog kayıtlarını bulamayabilir. Bu durumda secondary normal replication ile primary’yi yakalayamaz ve genellikle yeniden initial sync gerekir.
23 günlük süre dolmadan açılırsa, primary’den eksik oplog kayıtlarını okuyarak kendini güncel hale getirebilir.
Ayrıca oplog için yaklaşık 1809 MB alan tanımlı olduğu ve mevcut kullanımın yaklaşık 0.18 MB olduğu görülmektedir.
Replication Lag Kontrolü
Replica Set içinde Secondary node’ların Primary’den ne kadar geride olduğunu görmek için:
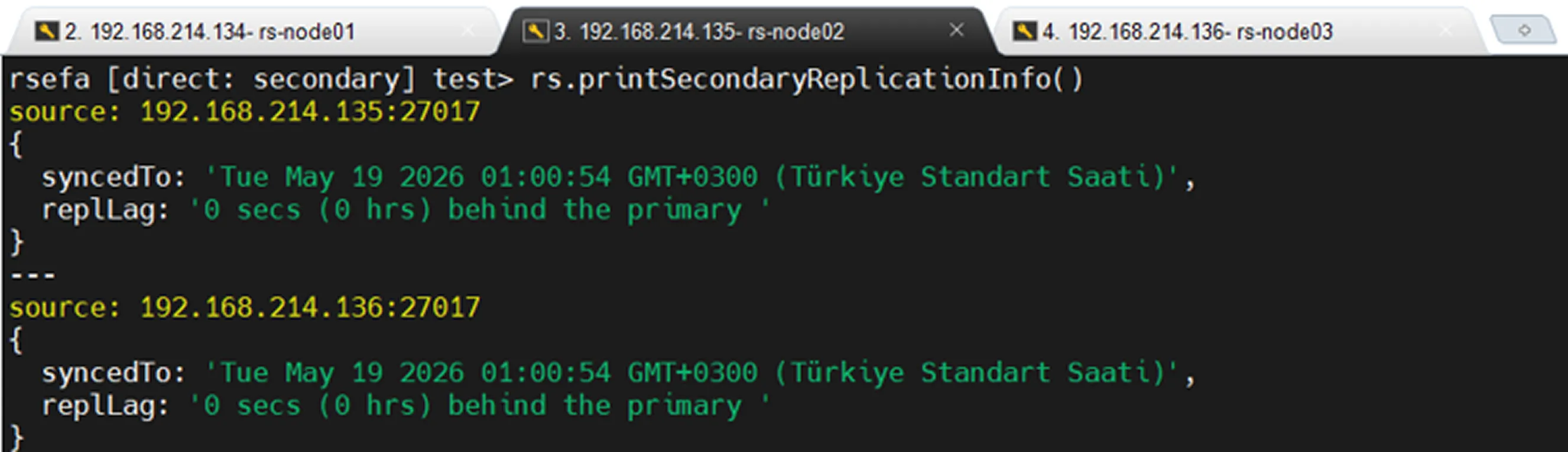
Yukarıdaki görselde Replica Set içinde arbiter bulunduğunu, arbiterin data tutamadığını (show dbs), oy hakkının olduğunu ve asla election aşamasında primary adayı olamayacağını (priority: 0) görüyoruz.
Sorgulamak için:
Majority, voting member sayısına göre hesaplanan minimum oy çoğunluğudur.
formülü ile hesaplanır.
Burada majority, cluster içindeki sağlıklı node sayısını vermez; Primary seçimi için gereken minimum oy sayısını ifade eder.
Eğer erişilebilir voting member sayısı majority değerinin altına düşerse yeni Primary seçilemez ve yazma işlemleri durur.
Floor, matematikte aşağı yuvarlama demektir.
Mimari Senaryolar
Replica Set mimari tercihi elde bulunan kaynaklara göre ve gereksinimlere göre farklı şekilde tasarlanabilir. En sık tercih edilen mimariler PSS (1 Primary 2 Secondary) ve PSA (1 Primary 1 Secondary 1 Arbiter)’dir. Bunlara ek olarak en az önerilen ve gereksiz görülen PSSA ve 1 Secondary Node’un FKM’de bulunduğu PSS tasarımıdır.
Şimdi bu tasarımların avantajlarını ve dezavantajlarını inceleyelim:
1- PSS (1 Primary 2 Secondary)
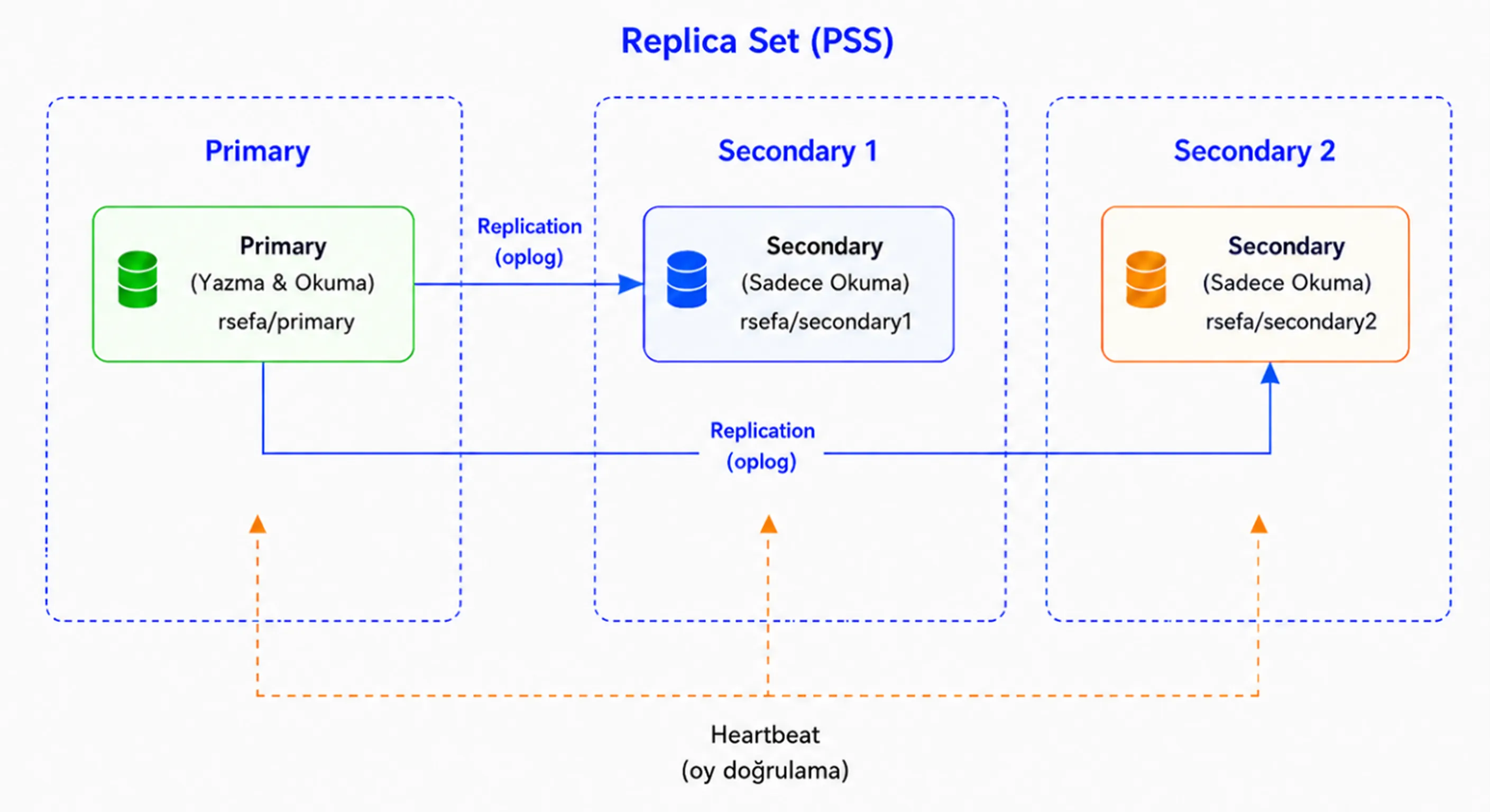
PSS mimarisinde veri 3 node üzerinde de tutulur. Yapıda 1 adet Primary node ve 2 adet Secondary node bulunur.
Primary node üzerinde bir arıza veya erişim problemi oluştuğunda, uygun Secondary node’lardan biri election sonucunda yeni Primary olarak seçilir. Böylece kısa süreli bir kesinti sonrasında sistem çalışmaya devam eder.
Bu mimaride 3 voting member bulunduğu için majority değeri 2’dir. Yani Primary seçimi yapılabilmesi için en az 2 voting member’ın erişilebilir durumda olması gerekir.
Eğer yeni Primary node da erişilemez hale gelirse geriye yalnızca 1 voting member kalır. Bu durumda majority sağlanamaz, son kalan node kendisini Primary olarak seçemez ve yazma işlemleri durur.
2- PSS (1 Primary 1 Secondary (DC) 1 Secondary (DRC))
Bu mimaride hem yüksek erişilebilirlik hem de felaket kurtarma açısından daha güvenli bir yapı elde edilir. Ancak farklı lokasyondaki Secondary node’un network gecikmesi, replikasyon lag değeri ve Primary olma ihtimali dikkatli şekilde planlanmalıdır.
Bu tasarım en çok önerilen mimari tasarımıdır. Çünkü hem veri 3 Node’da taşınır hem de Secondary sunuculardan birisi farklı lokasyonda olduğu için verilerin yeri daha güvenli olur.
3- PSA (1 Primary 1 Secondary 1 Arbiter)
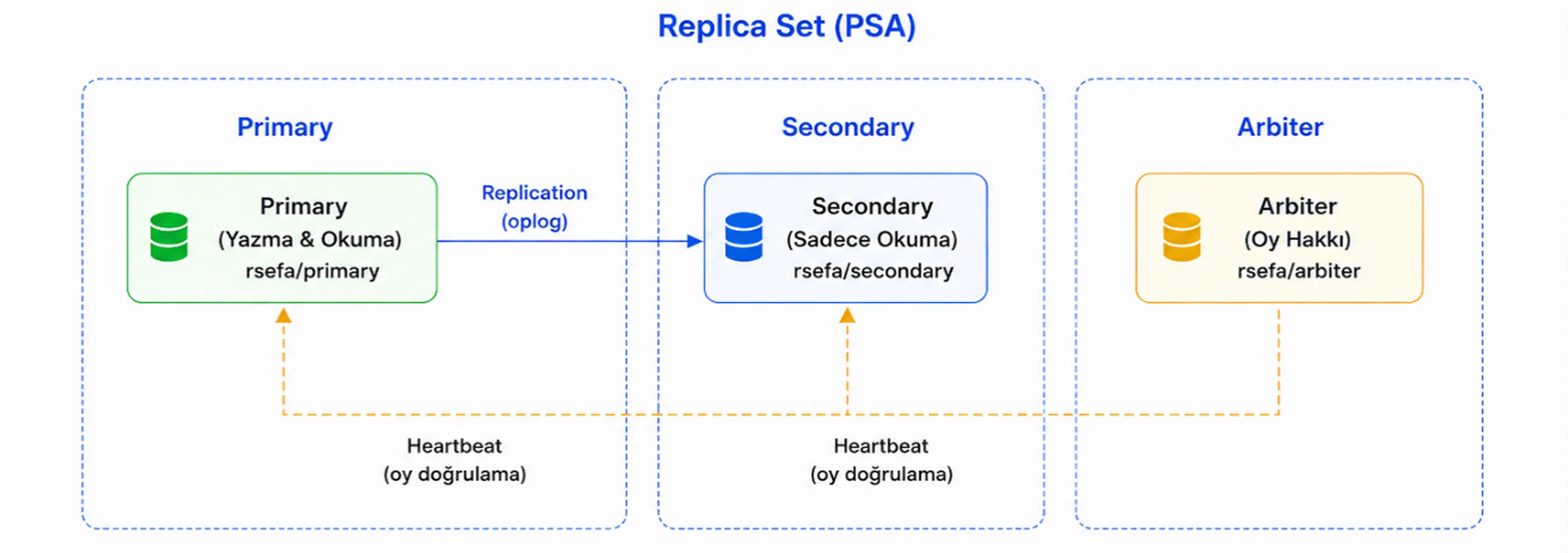
3. PSA (1 Primary, 1 Secondary, 1 Arbiter)
Kaynak yetersizliği nedeniyle ikinci bir Secondary node kullanılamıyorsa ancak Replica Set mimarisi kurulmak isteniyorsa PSA tasarımı tercih edilebilir. Bu yapıda bir adet Primary node, bir adet Secondary node ve bir adet Arbiter node bulunur.
Bu tasarımda Arbiter node veri tutmaz, oplog uygulamaz ve hiçbir zaman Primary olamaz. Görevi yalnızca election süreçlerinde oy kullanarak Primary seçimine katkı sağlamaktır.
Primary node erişilemez hale geldiğinde, Secondary node election sonucunda yeni Primary olarak seçilebilir. Ancak bu durumda geriye yalnızca yeni Primary ve Arbiter kaldığından veri kopyası barındıran tek bir node bulunur. Bu nedenle sistem çalışmaya devam etse de replikasyon yedekliliği geçici olarak kaybolur.
Primary ve Arbiter'in kaldığı bir senaryoda Arbiter da devre dışı kalırsa majority kaybedilir. Bu durumda mevcut Primary rolünü sürdüremez ve yazma işlemleri durur.
Benzer şekilde Primary kapanır ve yalnızca Arbiter ayakta kalırsa, Arbiter veri tutmadığı ve Primary olamadığı için cluster yazma işlemlerine devam edemez.
Özetle PSA mimarisi kaynak kısıtı bulunan ortamlarda kullanılabilir; ancak PSS mimarisi kadar güçlü bir veri yedekliliği sağlamaz. Bu nedenle mümkün olduğunda PSS tercih edilmeli, PSA ise bütçe veya kaynak kısıtlarının bulunduğu senaryolarda değerlendirilmelidir.
4. PSSA (1 Primary, 2 Secondary, 1 Arbiter)
PSSA mimarisinde bir adet Primary node, iki adet Secondary node ve bir adet Arbiter node bulunur.
İlk bakışta PSS mimarisine ek olarak bir Arbiter kullanmak daha güvenli gibi görünse de bu her zaman avantaj sağlamaz. Çünkü bu yapıda toplam dört voting member bulunur ve majority değeri üçtür.
Bu nedenle herhangi iki üyenin erişilemez hale gelmesi durumunda majority kaybedilir. Majority sağlanamadığında yeni bir Primary seçilemez veya mevcut Primary rolünü sürdüremez. Sonuç olarak yazma işlemleri durur.
Bu sebeple fazladan Arbiter kullanmak yerine çoğu durumda standart PSS mimarisinin tercih edilmesi daha doğru olur. PSS yapısında veri üç node üzerinde tutulur ve majority sağlamak için Arbiter'a ihtiyaç duyulmaz.
Arbiter, sürekli cluster içerisinde aktif bir üye olarak tutulmak yerine olağanüstü durumlarda hızlıca devreye alınabilecek yedek bir bileşen olarak planlanabilir. Örneğin bir node arızalandığında geçici olarak Replica Set'e eklenebilir. Ancak bu işlemler dikkatli yapılmalı ve Replica Set konfigürasyonu kontrollü şekilde güncellenmelidir.
Özetle PSSA mimarisi çoğu senaryoda PSS'e göre belirgin bir avantaj sağlamaz. Hatta voting member sayısını artırdığı için majority gereksinimini yükseltir ve bazı hata senaryolarında cluster'ın yazma işlemlerini durdurmasına neden olabilir.
RS Komutları
MongoDB Replica Set yönetiminde sık kullanılan bazı rs komutları aşağıda listelenmiştir.
rs.status()
Replica Set üyelerinin anlık durumunu görüntüler. Node'ların Primary, Secondary veya Arbiter olup olmadığı, health bilgileri, replication durumu ve election detayları bu komut ile görülebilir.
rs.isMaster()
Bağlı olunan MongoDB node'unun Replica Set içerisindeki rolünü gösterir. Node'un Primary olup olmadığı, Secondary durumu ve bağlantı bilgileri görüntülenebilir.
Not: Yeni MongoDB sürümlerinde
rs.isMaster()yerinehellokomutu tercih edilmektedir.
rs.conf()
Replica Set konfigürasyonunu görüntüler. Üyelerin host, priority, votes ve arbiterOnly gibi ayarları bu komut ile incelenebilir.
rs.initiate()
Yeni bir Replica Set başlatmak için kullanılır. Replica Set ilk kez oluşturulurken çalıştırılır.
rs.add()
Replica Set'e yeni bir data-bearing member eklemek için kullanılır. Genellikle yeni bir Secondary node eklemek amacıyla kullanılır.
rs.addArb()
Replica Set'e yeni bir Arbiter node eklemek için kullanılır. Arbiter veri tutmaz ve yalnızca election süreçlerinde oy kullanır.
rs.remove()
Replica Set içerisinden bir üyeyi çıkarmak için kullanılır. Bu üye bir Secondary veya Arbiter olabilir.
rs.reconfig()
Replica Set konfigürasyonunda yapılan değişiklikleri uygulamak için kullanılır. Özellikle priority, votes, hidden ve arbiterOnly gibi ayarlar değiştirildiğinde kullanılır.
rs.stepDown()
Mevcut Primary node'un Primary rolünden ayrılmasını sağlar. Ardından uygun bir Secondary node yeni Primary olarak seçilebilir.
rs.freeze()
Bağlı olunan Secondary node'un belirli bir süre boyunca Primary adayı olmasını engeller. Genellikle bakım veya kontrollü failover işlemlerinde kullanılır.
rs.printReplicationInfo()
Oplog boyutunu, oplog başlangıç ve bitiş zamanlarını, ayrıca oplog window bilgisini gösterir. Oplog'un ne kadar geçmiş veri tuttuğunu görmek için kullanılır.
rs.printSecondaryReplicationInfo()
Secondary node'ların Primary'ye göre replication lag bilgisini gösterir. Replikasyon gecikmelerini analiz etmek için kullanılır.
rs.syncFrom("IP:PORT")
Bir Secondary node'un hangi üyeden veri senkronize edeceğini manuel olarak belirlemek için kullanılır. Normal şartlarda MongoDB bu işlemi otomatik yönettiğinden dikkatli kullanılmalıdır.
Kurulum Adımları
1. Tüm Sunuculara MongoDB Kurulumu
2. Firewall ve SELinux'u Devre Dışı Bırakma
Kontrol etmek için:
Kontrol etmek için:
3. Replica Set Konfigürasyonu
Tüm sunucularda aşağıdaki ayar yapılmalıdır:
4. Replica Set'i Başlatma
Herhangi bir sunucuda mongosh bağlantısı açıldıktan sonra aşağıdaki komut çalıştırılır:
Kurulum Sonrası Testler
Primary Read/Write Testi
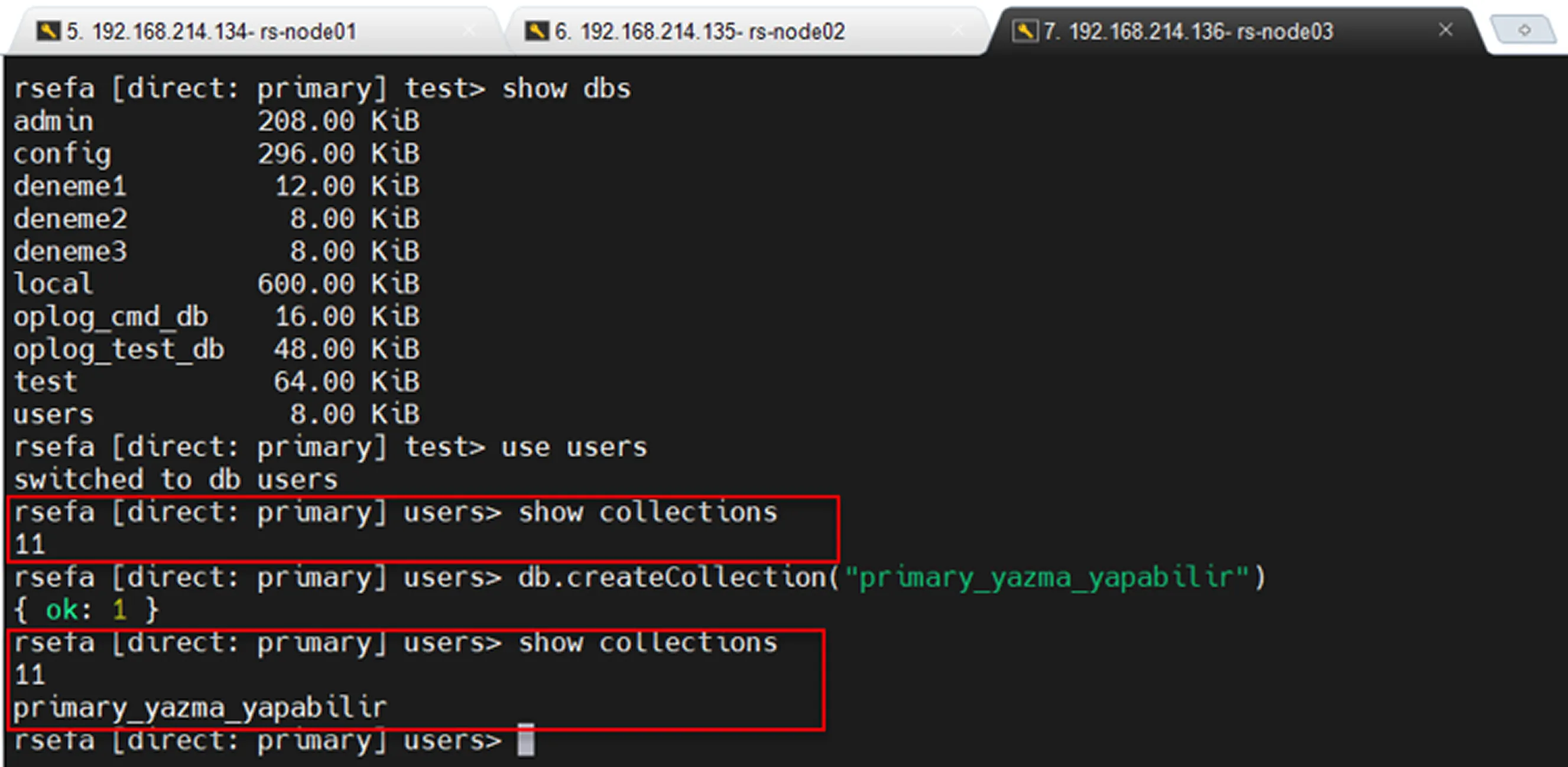
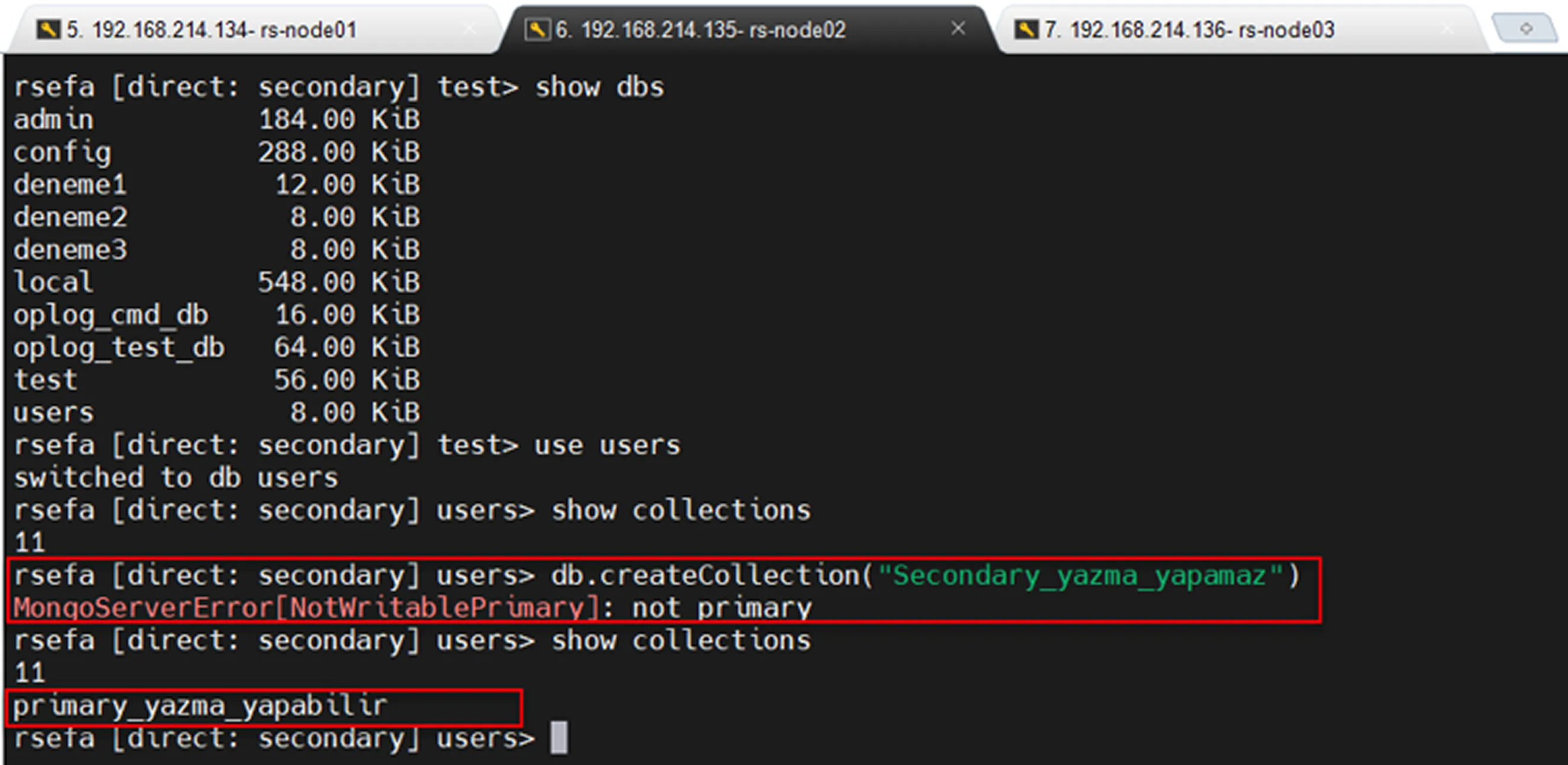
Secondary read only ve replication testi
Automatic Failover Testi
Primary sunucuda mongod servisi durdurulduğunda, majority sağlanıyorsa Secondary sunuculardan biri otomatik olarak Primary rolünü üstlenir. Ancak election süreci gerçekleşirken kısa süreli bir servis kesintisi yaşanabilir.
Eğer ortada bir felaket senaryosu bulunmuyorsa ve liderlik değişimi kontrollü şekilde gerçekleştirilmek isteniyorsa, manuel failover uygulanması genellikle daha uygun bir yöntemdir.
Manual Failover Testi
Manual failover işlemi iki farklı yöntemle gerçekleştirilebilir.
İlk yöntem, mevcut Primary sunucuya bağlandıktan sonra aşağıdaki komutu çalıştırmaktır:
Bu komut çalıştırıldığında mevcut Primary liderlik rolünü bırakır. Ardından uygun Secondary node'lar arasında yeni bir election süreci başlatılır ve yeni bir Primary seçilir.
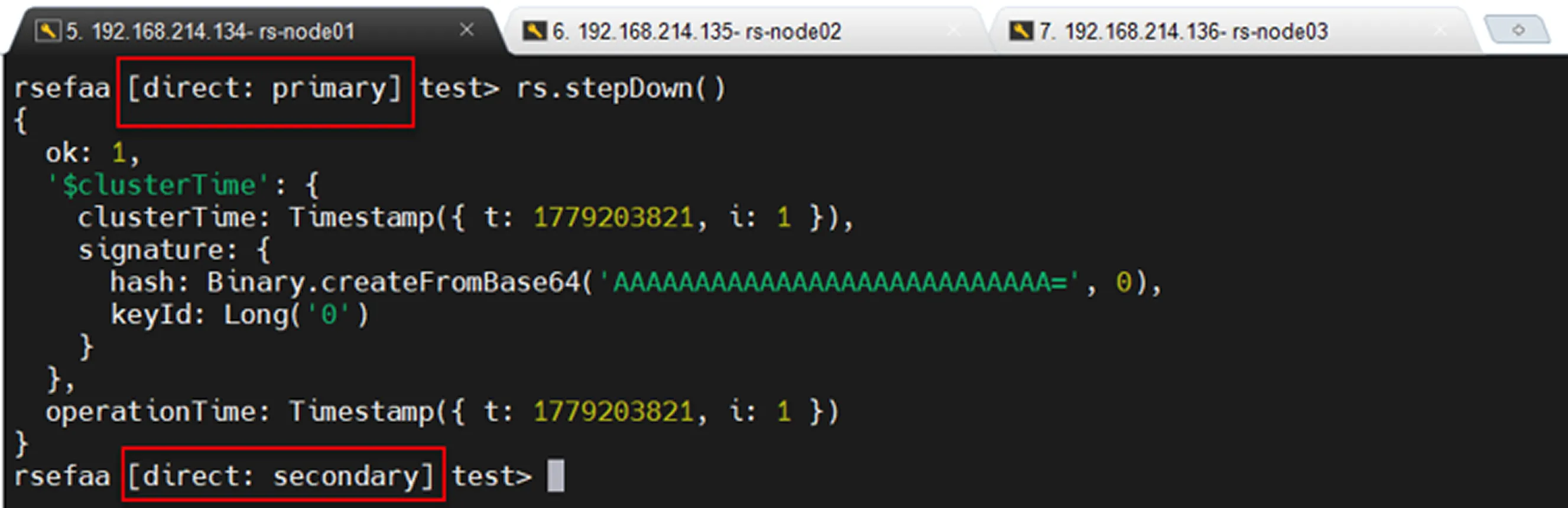
Priority Değiştirerek Manual Failover
İkinci yöntemde sunucuların priority değerleri güncellenir. En yüksek priority değerine sahip sunucu, Primary olmaya en yakın aday olarak düşünülebilir.
Priority değerleri kurulum sırasında tanımlanabileceği gibi daha sonra da değiştirilebilir. Kurulum sırasında bu değerleri priority parametresi ile belirlemiştik.
1= Varsayılan değer2= Primary olmaya öncelikli aday0= Mümkün olduğunca Primary olmaz (genellikle felaket kurtarma merkezi sunucuları için önerilir)
Eğer kurulum sırasında priority değerleri tanımlanmadıysa, mevcut Primary üzerinde aşağıdaki işlemler gerçekleştirilebilir:
Bu işlem sonrasında Replica Set yeni priority değerlerine göre değerlendirme yapar ve gerekli durumlarda Primary değişebilir.
Load Balancing
Replica Set mimarilerinde önerilen yaklaşım, uygulamanın doğrudan MongoDB driver üzerinden Replica Set üyelerine bağlanmasıdır.
Önerilen bağlantı formatı aşağıdaki gibidir:
Bu yapıda MongoDB driver:
Mevcut Primary node'u otomatik olarak algılar.
Failover sonrasında yeni Primary'ye yönlenir.
Read preference ayarlarına göre okuma trafiğini dağıtabilir.
Bu nedenle Replica Set önüne klasik bir TCP load balancer yerleştirmek çoğu durumda gerekli değildir. Hatta yanlış yapılandırılmış bir load balancer, yazma işlemlerini yanlışlıkla bir Secondary node'a yönlendirerek hatalara neden olabilir.
Bununla birlikte aşağıdaki özel durumlarda HAProxy veya benzeri çözümler tercih edilebilir:
Uygulama yalnızca tek host tanımı destekliyorsa
Replica Set connection string desteği bulunmuyorsa
Bağlantı yönetiminin merkezi hale getirilmesi gerekiyorsa
Replica Set için önerilen mimari yaklaşım:
Kullanıcıları veya uygulamaları doğrudan belirli bir Primary IP adresine bağlamak doğru bir yöntem değildir. Çünkü Primary rolü zaman içerisinde değişebilir.
Doğru bağlantı örneği:
Yanlış veya riskli bağlantı örneği:
Çünkü mongo1 daha sonra Secondary rolüne geçerse uygulama yazma işlemlerinde hata almaya başlayabilir.
Node Ekleme ve Çıkarma
Replica Set'e yeni bir node eklemeden önce ilgili sunucunun veri dizini temizlenmelidir.
Eğer mevcut veri dizini temizlenmeden node Replica Set'e eklenirse, mevcut veriler ile replikasyon verileri çakışabilir ve cluster içerisinde tutarsızlıklara neden olabilir.
Bir node'u Replica Set'ten çıkarmak için aşağıdaki komut kullanılabilir:
Bu komut belirtilen node'u Replica Set üyeliğinden kaldırır.
MongoDB güvenlik amacıyla bir node'un kendisini Replica Set'ten çıkarmasına izin vermez. 😊
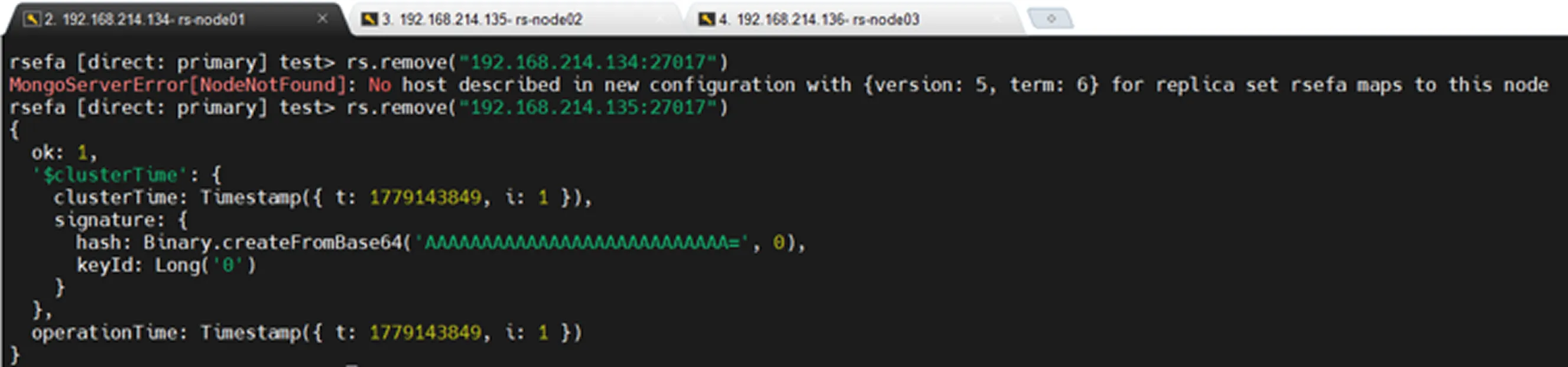
Kaldırma işleminden önce ve sonrasında sorgulanan db.hello() komutu ile Replica Set’den ayırma işleminin başarılı olduğunu görüyoruz:
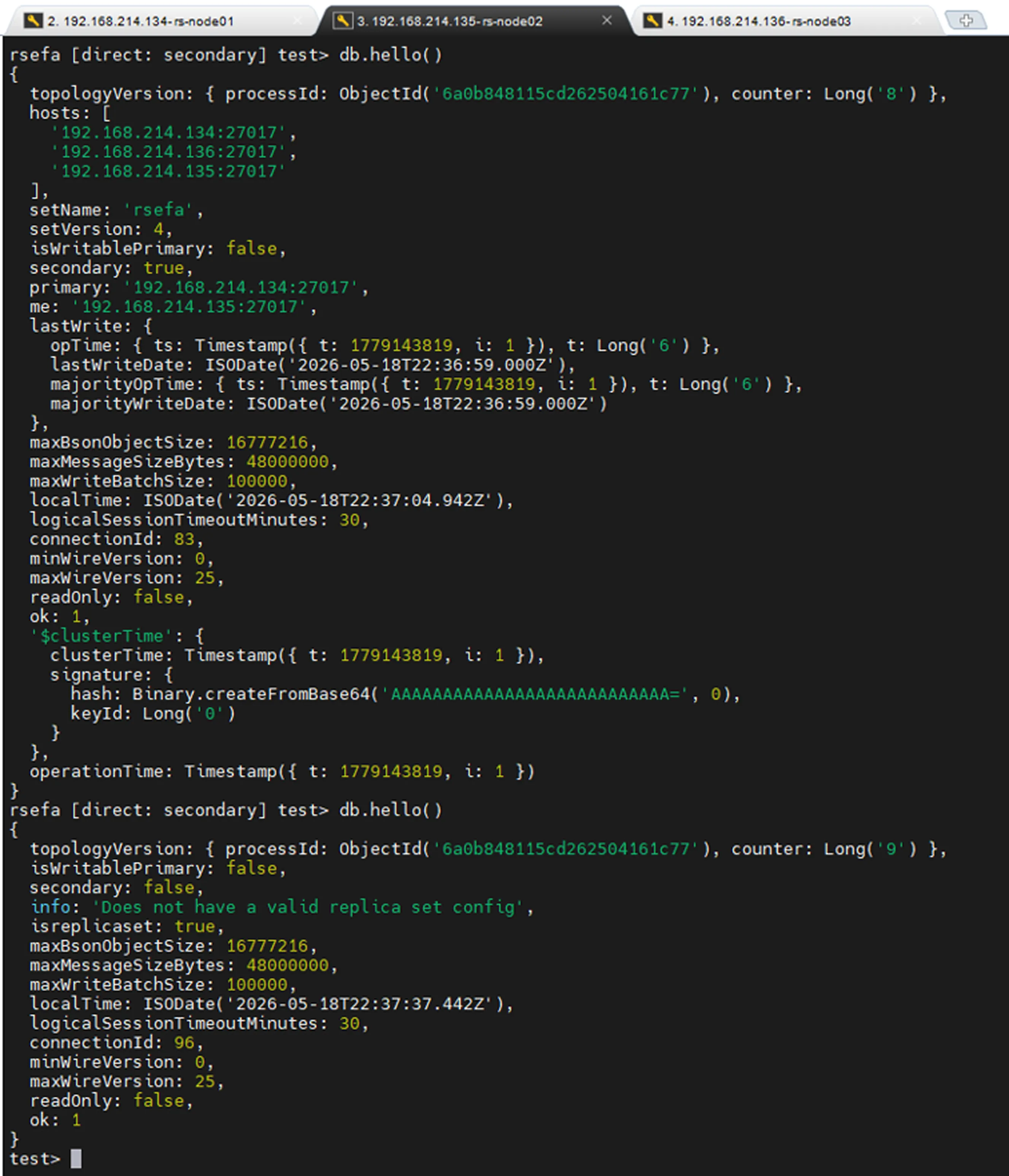
Yeni Bir Node Ekleme
Yeni bir node Replica Set'e eklenmeden önce, cluster tutarlılığını korumak amacıyla ilgili sunucunun veri dizini temizlenmelidir.
Temizlenmemiş bir veri dizini ile Replica Set'e katılım sağlanması, mevcut veriler ile replikasyon verilerinin çakışmasına ve veri tutarsızlıklarına neden olabilir.
Bu nedenle node durdurulur, veri dizini temizlenir ve ardından Replica Set'e tekrar eklenir.
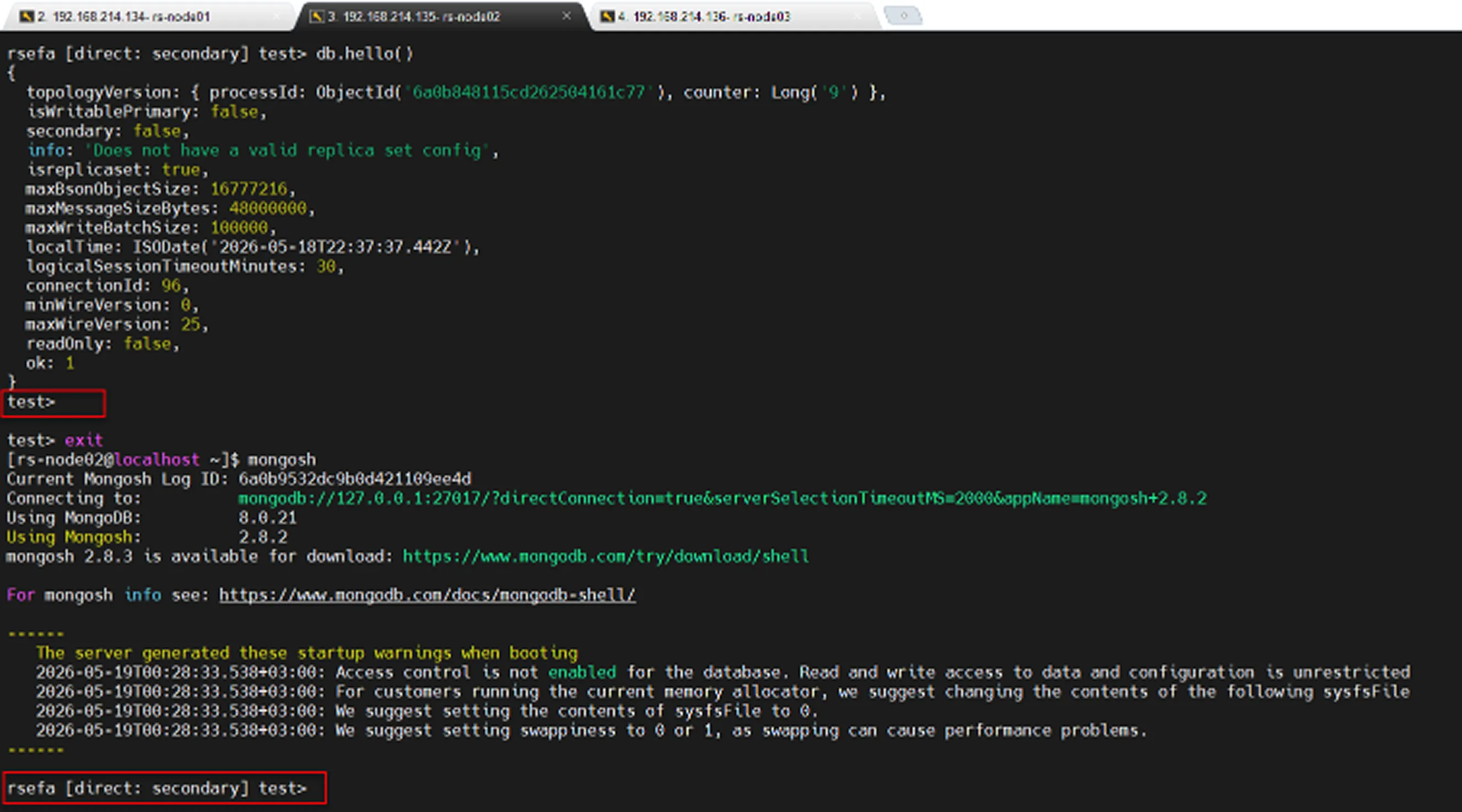
Yukarıdaki görselde görüldüğü gibi Replica Set’den ayırdığımız Node’u tekrardan Replica Set’e dahil ettik.




